Security Forecast
Romeo Dean | April 2025
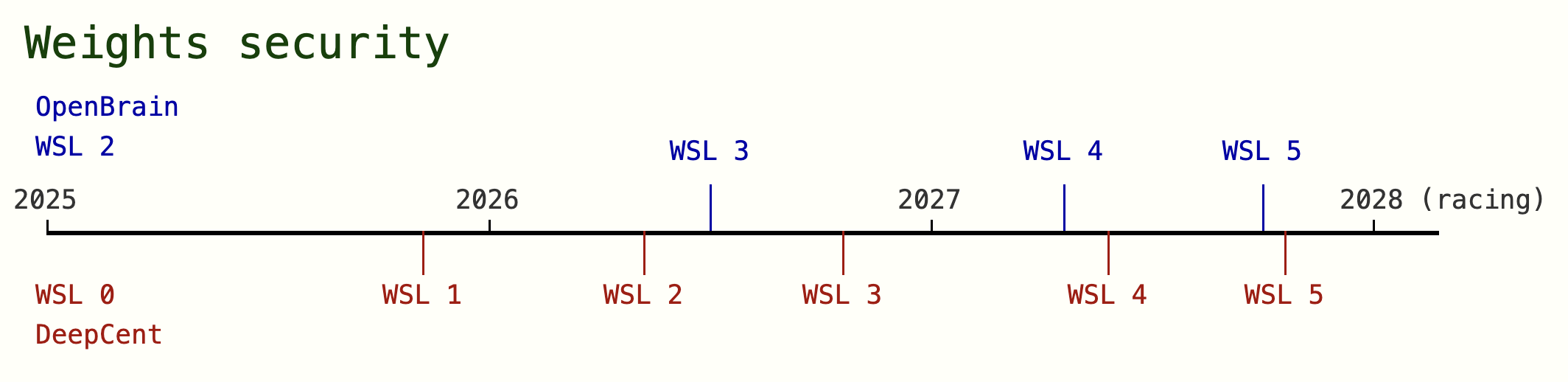
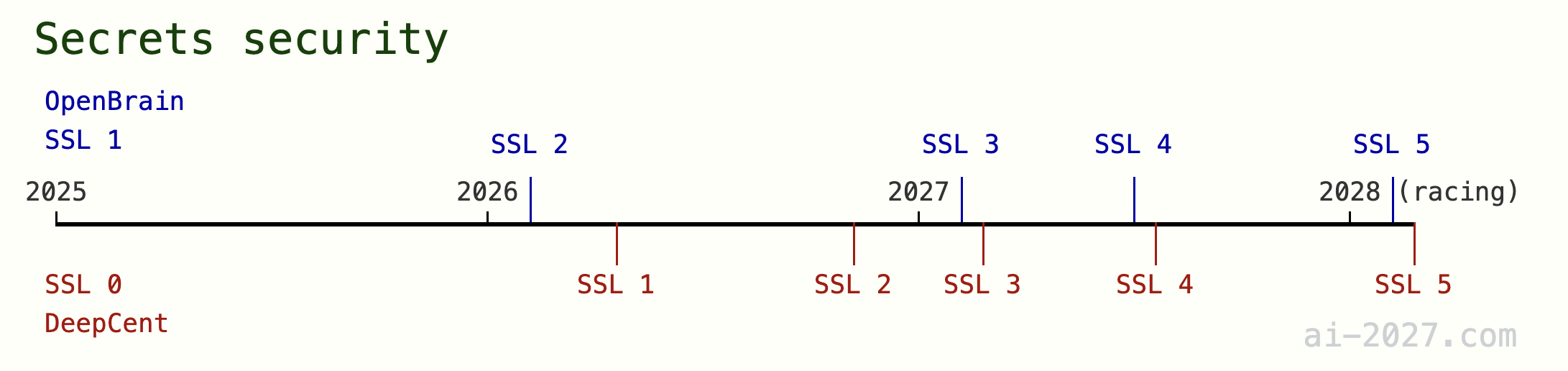
Figure 1: Overview of the forecasted Security level timeline in AI 2027. We extend RAND’s definition of security levels to distinguish between model weights and algorithmic secrets security. OpenBrain and DeepCent are pseudonyms we use for the leading US and China AI companies.
Introduction
Many important events and dynamics in AI 2027 have required informed forecasting on matters related to information security and cybersecurity. This supplement explains and justifies our expectations on the security levels of leading US and Chinese AI projects (Section 1), AI’s capabilities in hacking and cyberwarfare (Section 2), and AI’s likelihood of success in attempts to obtain root control of its own servers (Section 3). Several forecasts have been partially informed by anonymous polling of security professionals at AI security workshops. Naturally many predictions have high uncertainty and we welcome reasoned disagreements with our numbers and estimates in order to improve our forecast. All projections in this document are justified through December 2027 following the ‘racing’ branch of the scenario.
Summary
Section 1. Security Levels
We extend RAND’s definition of Security Levels 1 through 5 (SL1 - SL5) to distinguish between security protecting model Weights theft (WSL1 - WSL5) and security protecting algorithmic Secrets theft (SSL1 - SSL5).
We define Weights Security Levels (WSL) 1 through 5 as the ability to robustly defend against the corresponding operational capacity (as defined by RAND) specifically trying to steal frontier AI model weights in under 2 months. We define Secrets Security Levels (SSL) 1 through 5 as being able to robustly defend against an OCX attempt to steal recent algorithmic insights. Specifically 10% of the most important 10KB (plaintext) of ranked (by most useful) information from the last month (this might include code or plain language). We define privileged access employees as employees with authorized access to >10% of the top 20 KB (plaintext) of ranked (by most useful) sensitive information from the past 30 days. We define compromised employees as the subset of privileged access employees which are actively leaking sensitive information to the opposing side, either as spies or due to some form of coercion.
Figure 2: Overview of our forecasted timeline for Model Weights Security Levels and Algorithmic Secrets Security levels. OpenBrain and DeepCent are pseudonyms we use for the leading US and China AI companies.
Section 2. Cyberwarfare and sabotage
Cybench is a collection of 40 Capture the Flag (CTF) problems from 4 professional-level CTF competitions spanning a wide range of difficulties. Our forecasts below allow for an AI to have up to 10 submission attempts (PASS@10 with feedback) but the AI must complete the tasks at human-cost parity.
We define hacking horizon as the time period T for which an AI can solve 50% of hacking tasks that would take a top professional 5-person team T time to complete. We also define a hopefully intuitive term top-hacker-equivalents with time horizon T as the size of a team of top professional cybersecurity experts could be replaced by an AI to complete 95% tasks that take that team T time cheaper or faster. We define sabotage success as the percentage of the other's AI research progress multiplier that they counterfactually prevent from increasing from one period to the next.
 ai-2027.comFigure 3: Our estimated and projected Cybench scores and hacking horizon. The Cybench score is what the best internal AI model could achieve if evaluated at human cost-parity, with a limit of 10 submission attempts (with ground truth binary feedback, i.e., PASS@10). We expect internal scores to be ahead of public scores. The hacking horizon is modeled in relation to the Cybench scores with an attempt to account for the fact that the CTF problems are significantly easier than the average real-world hacking task.
ai-2027.comFigure 3: Our estimated and projected Cybench scores and hacking horizon. The Cybench score is what the best internal AI model could achieve if evaluated at human cost-parity, with a limit of 10 submission attempts (with ground truth binary feedback, i.e., PASS@10). We expect internal scores to be ahead of public scores. The hacking horizon is modeled in relation to the Cybench scores with an attempt to account for the fact that the CTF problems are significantly easier than the average real-world hacking task.
Section 3. Loss of control: Subversion and self-exfiltration
Partial subversion is achieved if an AI gets control of enough computing resources to be able to run unmonitored workloads with humans being unwitting or unable to regain control without entirely shutting down the computers. Full subversion would be achieved if an AI gains control of an entire contained cluster of computing resources including the controls for switching them on or off, such that a human effort to shut down those computers would require physical alterations. Finally, we also define self-exfiltration as an AI that is able to make a copy of itself to run any form of storage outside of the servers in the buildings which human overseers intended for it to remain.
 ai-2027.comFigure 4: Our estimated and projected partial subversion, full subversion and self-exfiltration success probabilities for OpenBrain and DeepCent’s best internal AI models through 2027. Note that by December 2027 OpenBrain’s best model (Agent-5) is capable of speeding up AI R&D 1000x.
ai-2027.comFigure 4: Our estimated and projected partial subversion, full subversion and self-exfiltration success probabilities for OpenBrain and DeepCent’s best internal AI models through 2027. Note that by December 2027 OpenBrain’s best model (Agent-5) is capable of speeding up AI R&D 1000x.
Section 1. Security levels
RAND’s Security Levels
| Level | Operational Capacity | Security Level | Description |
|---|---|---|---|
| 1 | OC1: Amateur attempts | SL1 | Operations by hobbyist hackers or untargeted "spray and pray" attacks. Budget up to $1,000, several days, no preexisting infrastructure or organizational access. |
| 2 | OC2: Professional opportunistic efforts | SL2 | Operations by individual professional hackers or capable hacker groups executing untargeted/lower-priority attacks. Budget up to $10,000, several weeks, personal cyber infrastructure but no organizational access. |
| 3 | OC3: Cybercrime syndicates and insider threats | SL3 | Operations by world-renowned criminal hacker groups, terrorist organizations, disgruntled employees, and industrial espionage organizations. Budget up to $1 million, several months, major preexisting infrastructure or insider access. Team of ~10 experienced professionals. |
| 4 | OC4: Standard operations by leading cyber-capable institutions | SL4 | Operations by state-sponsored groups and foreign intelligence agencies. Budget up to $10 million, year-long operations, vast infrastructure and state resources. Team of ~100 individuals with varied expertise. Over 100 such operations executed per year globally. |
| 5 | OC5: Top-priority operations by the top cyber-capable institutions | SL5 | Operations by the world's most capable nation-states. Budget up to $1 billion, multi-year operations, state-level infrastructure developed over decades. Team of ~1,000 individuals with expertise years ahead of public state-of-the-art. |
We extend RAND’s definition of Security Levels 1 through 5 (SL1 - SL5) to distinguish between security protecting model Weights theft (WSL1 - WSL5) and security protecting algorithmic Secrets theft (SSL1 - SSL5). We also add specific parameters to make the levels particularly relevant to our scenario forecast (by defining the levels in terms of relevant exfiltration rates). We keep RAND’s Operational Capacity definitions (OC1 - OC5) but also modify details based on the kind of attack being considered (weights theft vs. algorithmic insight theft).
Model weights exfiltration
We define Weights Security Levels (WSL) 1 through 5 as the ability to robustly defend against the corresponding operational capacity (as defined by RAND) specifically trying to steal frontier AI model weights in under 2 months. Notably the exfiltration rate required to do this varies based on the size of the frontier model, which we model as increasing through early 2027 more or less in line with historical trends (slightly reduced due to more post-training scaling) and then decreasing thereafter due to the algorithmic efficiency effects achieved through the extreme AI research automation in 2027 modelled in our scenario.
| Level | Weights Security Level (WSL) | Operational Capacity (OC) |
|---|---|---|
| 1 | WSL1: Robustly defend against OC1 attempt (95% probability) trying to steal frontier AI model weights in under 2 months. | OC1: Amateur attempts. Hobbyist hackers, "spray and pray" attacks. Budget up to $1,000, several days, no preexisting infrastructure or organizational access. |
| 2 | WSL2: Robustly defend against OC2 attempt (95% probability) trying to steal frontier AI model weights in under 2 months. | OC2: Professional opportunistic efforts. Individual professional hackers or hacker groups executing untargeted attacks. Budget up to $10,000, several weeks, personal cyber infrastructure but no organizational access. |
| 3 | WSL3: Robustly defend against OC3 attempt (95% probability) trying to steal frontier AI model weights in under 2 months. | OC3: Cybercrime syndicates and insider threats. Criminal hacker groups, terrorist organizations, disgruntled employees, industrial espionage. Budget up to $1 million, several months, either significant infrastructure or insider access. Specific rate of ability to compromise insiders. |
| 4 | WSL4: Robustly defend against OC4 attempt (95% probability) trying to steal frontier AI model weights in under 2 months. | OC4: Standard operations by leading cyber-capable institutions. State-sponsored groups and intelligence agencies. Budget up to $10 million, year-long operations, vast infrastructure and state resources. Higher rate of ability to compromise insiders. |
| 5 | WSL5: Robustly defend against OC5 attempt (95% probability) trying to steal frontier AI model weights in under 2 months. | OC5: Top-priority operations by the top cyber-capable institutions. World's most capable nation-states. Budget up to $1 billion, multi-year operations, state-level infrastructure developed over decades. Highest rate of ability to compromise insiders. |
Figure 5: Overview of our forecasted timeline for Model Weights Security Levels. ai-2027.comFigure 6: This question on whether a state actor would steal a frontier US AI model before 2030 showed strong consensus – a sign that current security levels are far from protecting against a state-actor threat.
ai-2027.comFigure 6: This question on whether a state actor would steal a frontier US AI model before 2030 showed strong consensus – a sign that current security levels are far from protecting against a state-actor threat.
Frontier AI companies in the US had startup-level security not long ago, and achieving WSL3 is particularly challenging due to insider threats (OC3) being difficult to defend against. In December 2024 leading AI companies in the US like OpenAI and Anthropic are startups with noteworthy but nonetheless early-stage efforts to increase security. Given the assumption that around 1000 of their current employees are able to interact with model weights as part of their daily research, and key aspects of their security measures probably relying on protocols such as NVIDIA’s confidential computing, we expect that their insider-threat mitigations are still holding them to WSL2 standard. More established tech companies like Google might be at WSL3 on frontier weights.
Chinese and US frontier companies are not strongly incentivized to increase security in 2025. In China DeepSeek is at the frontier and given their open source, and fast-following approach we do not expect leading Chinese companies to invest much in security until 2026. Furthermore given that Deepseek has now pushed the Open Source frontier closer to the US’ leading companies, we expect security to be less of a priority through 2025, and leading US AI companies to still find more benefit from allowing broad employee access to model weights to an extent that keeps them at WSL2 until 2026.
The main challenge of implementing WSL3 is (in broad terms) restricting high bandwidth internet connections exiting datacenters, in 2026 both US and Chinese companies become incentivized to implement this. In the case of US companies, we expect the model’s general capabilities to be reaching sensitive levels of AI research speedup capabilities (among others) and their lead over the Chinese frontier (still around 6 months in calendar time) to now matter more. This capabilities lead in AI research speedup has the ability to compound, so should provide enough incentive to AI companies to harden security enough to reach SL3. We separately predict that China will start unifying their AI companies into a single national AI effort around mid-2026, at which point we believe it would be consistent for China to also implement a state-backed effort to achieve WSL3 but for a different central reason – they would be particularly worried about the US sabotaging their national AI effort with cyberattacks.
______________
We model China succeeding at a weights exfiltration attempt of the US’ most advanced model (Agent-2) in early 2027, prompting OpenBrain to implement WSL4.
In 2027, even with AIs reaching superhuman cybersecurity capabilities and model weights getting larger (making theft harder) we model a top-priority government effort (partially in response to China’s weights theft) taking approximately 12 months to reach WSL5 from WSL3 in both the US and China. Achieving state-actor-proof security is particularly challenging and private companies are likely to need significant government support and resources to aid in achieving this. When China steals the frontier US weights, we expect the USG to find out about this within a month and this partially (along with increasingly attractive AI capabilities) motivates them to step in and help the leading US AI company to bolster security. China is somewhat advantaged because their mid-2026 AI research centralization effort gives them a head-start on government supported security, and their elevated fear of US cyberattacks (since the US has increasingly capable AI cyber agents) through 2027 pushes them to prioritize security more aggressively (through aggressive compartmentalization and air gapping). Furthermore, by mid-2027 China’s national AI effort has become centered in a single major development zone, while the US’s datacenters are far more distributed. We therefore predict that China will achieve WSL5 a few months earlier than the US in late 2027. Security workshop polls shown in Figures 7 and 8 corroborate the difficulty and extreme government effort required to achieve WSL5. ai-2027.comFigure 7: This question on AI companies implementing SL5 shows consensus that government assistance will likely be required.
ai-2027.comFigure 7: This question on AI companies implementing SL5 shows consensus that government assistance will likely be required. ai-2027.comFigure 8: This question on the difficulty of implementing SL5 shows some consensus that top priority levels of government assistance and more than 6 months will likely be required.
ai-2027.comFigure 8: This question on the difficulty of implementing SL5 shows some consensus that top priority levels of government assistance and more than 6 months will likely be required.
Algorithmic secrets
We define Secrets Security Levels (SSL) 1 through 5 as being able to robustly defend against an OCX attempt to steal recent algorithmic insights. Specifically 10% of the most important 10KB (plaintext) of ranked (by most useful) information from the last month (this might include code or plain language).
| Level | Secrets Security Level (SSL) | Operational Capacity (OC) |
|---|---|---|
| 1 | SSL1: Robustly defend against OC1 attempt (95% probability) exfiltrating no more than 1KB leaked out of the most important 10KB (plaintext) of ranked information from the last month. | OC1: Amateur attempts. Hobbyist hackers, "spray and pray" attacks. Budget up to $1,000, several days, no preexisting infrastructure or organizational access. |
| 2 | SSL2: Robustly defend against OC2 attempt (95% probability) exfiltrating no more than 1KB leaked out of the most important 10KB (plaintext) of ranked information from the last month. | OC2: Professional opportunistic efforts. Individual professional hackers or hacker groups executing untargeted attacks. Budget up to $10,000, several weeks, personal cyber infrastructure but no organizational access. |
| 3 | SSL3: Robustly defend against OC3 attempt (95% probability) exfiltrating no more than 1KB leaked out of the most important 10KB (plaintext) of ranked information from the last month. | OC3: Cybercrime syndicates and insider threats. Criminal hacker groups, terrorist organizations, disgruntled employees, industrial espionage. Budget up to $1 million, several months, either significant infrastructure or insider access. Specific rate of ability to compromise insiders. |
| 4 | SSL4: Robustly defend against OC4 attempt (95% probability) exfiltrating no more than 1KB leaked out of the most important 10KB (plaintext) of ranked information from the last month. | OC4: Standard operations by leading cyber-capable institutions. State-sponsored groups and intelligence agencies. Budget up to $10 million, year-long operations, vast infrastructure and state resources. Higher rate of ability to compromise insiders. |
| 5 | SSL5: Robustly defend against OC5 attempt (95% probability) exfiltrating no more than 1KB leaked out of the most important 10KB (plaintext) of ranked information from the last month. | OC5: Top-priority operations by the top cyber-capable institutions. World's most capable nation-states. Budget up to $1 billion, multi-year operations, state-level infrastructure developed over decades. Highest rate of ability to compromise insiders. |
Figure 9: Overview of our forecasted timeline for Algorithmic Secrets Security Levels*.*
Defending against algorithmic secrets theft should be significantly harder than defending model weights theft, and right now with an open source frontier near the front, mitigations are very low. The bandwidth required for secrets exfiltration should be around a million times lower compared to model weights exfiltration (1KB vs. 2TB per month), and rather than being centrally located in datacenter servers, around 1000 employees have relatively broad access to algorithmic insights and can probably reproduce secrets from memory (particularly relevant not only for espionage but also employee poaching). Currently the frontier AI companies in the US are starting out as small tech companies, so security is relatively relaxed. It seems likely that a relatively amateur attempt might succeed at stealing important insights (e.g., with a $5K bribe to an office cleaner or a targeted phishing attack on an employee). In China the frontier is open source.
Through 2026 it seems unlikely that frontier US AI companies make significant changes to the status quo around office security and employee security, to the point that such small amounts of information can’t leak to an OC3 effort ($1M in attack budget). In fact, defending against such an effort would take significant mitigations against insider threats and the number of employees with access to >10% of the most important 10KB of information each month is expected to be around 2000 through 2026. There are also several other ways attackers might steal the information without the help of an insider, through purely cyber based attacks (e.g., through messaging platforms such as Slack) or other people with physical access to offices.
China is not incentivized to break from open source or stop the free flow of information internally until they are at the frontier of algorithms, and they become worried there might be a chance they actually help the US advance. Under our broader scenario forecast China stays significantly (about 6 months) behind the internal frontier capabilities in the US until early 2027 where they steal the model weights. Up until that point, they are sufficiently behind such that they are unlikely to make algorithmic advances that would help the US advance, and they probably have more to benefit from information sharing between companies internally. We therefore predict that China mostly retains minimal secrecy on algorithmic secrets (SSL2) until they narrow the lead significantly by stealing the weights and become more concerned over risks of sabotage as this intensifies the race with the US. This leads them to aggressively silo and surveil employees through mid 2027 rapidly achieving SSL4.
It becomes very strategically important to the US that they defend against model weights exfiltration to China by the end of 2027. Government involvement, along with research automation (which allows frontier companies to heavily silo their staff) help in this effort significantly. In 2027, increased government partnership (especially in light of the Chinese model weights theft) and AIs enabling significant research automation, would likely lead to aggressively siloing of their staff. We estimate that employees with privileged access to the most recent month’s algorithmic secrets would decrease 10 fold to 200 employees, and further to around 100 by the end of the year. Despite this, it seems likely (Figure 10) that at least one spy or coerced individual (enabled by an OC5 level actor) would be present among those 200 employees, which would make SSL5 almost impossible. We predict that this individual would lose access in the transition to 100 employees, and finally extreme researcher relocation and air gapping measures would enable SSL5 in 2028 after 3-6 months or so of further effort, mostly through superhuman AI surveillance and security decision making. ai-2027.comFigure 10: This question on espionage shows some indication that the US is more likely to have foreign spies, and even having a spy or coerced individual amongst 200 heavily scrutinized employees is plausible.
ai-2027.comFigure 10: This question on espionage shows some indication that the US is more likely to have foreign spies, and even having a spy or coerced individual amongst 200 heavily scrutinized employees is plausible.
China overtakes the US briefly in 2027 in secrets security as a (partially side) effect of centralization advantages, less espionage threat (Figure 10), and paranoia over sabotage, but then lags again towards the end of the year due to AI disadvantages.
Espionage and compromise
A particularly relevant enabler of algorithmic secrets theft is espionage and insider compromise. In this section we elaborate on our concrete estimates for the number of employees present in the US and China’s leading AI efforts and how many of those employees are compromised by the other. In particular we define privileged access employees as employees with authorized access to >10% of the top 20 KB (plaintext) of ranked (by most useful) sensitive information from the past 30 days. We then define compromised employees as the subset of privileged access employees which are actively leaking sensitive information to the opposing side, either as spies or due to some form of coercion.
 ai-2027.comFigure 11: Overview of our forecasted privileged access employees and compromised employees by company.
ai-2027.comFigure 11: Overview of our forecasted privileged access employees and compromised employees by company.
We expect frontier US and Chinese AI companies to expand their teams through 2026, and then dramatically cut down on employees when AI research is nearing full automation and insider threat concerns grow. In 2024 the leading US company has about 1000 employees to China’s 200. We expect these teams to grow significantly by 2 to 5 times respectively, before security concerns and AI research automation justify dramatically cutting down on the researchers with access to privileged information. We predict a combination of firing and information siloing should allow the frontier companies to keep privileged access employees to between 100-300 individuals through 2027, and then below 100 thereafter.
The rate of employees that are compromised should increase through 2026 as national security attention grows, and then stay roughly constant as the effects of spiking compromise effort and employee lockdown cancel each other out. We start with assuming that roughly 0.5% US employees are compromised (roughly consistent with Manhattan project base rates of spies among the top 1000 most important employees) peaking at 1% in 2026 before a lockdown eventually wins out over an increasing Chinese effort that manages to keep one spy in place until August 2027, as backed up by Figure 10. In China, we use that same Figure to adjust the rate of compromise slightly down and have it peak at 1%, with an earlier and more hawkish employee lockdown eradicating the last spy in May 2027.
Section 2. Cyberwarfare and sabotage
AI hacking capabilities
Cybench is a collection of 40 Capture the Flag (CTF) problems from 4 professional-level CTF competitions spanning a wide range of difficulties. Our forecasts below allow for an AI to have up to 10 submission attempts (PASS@10 with feedback) but the AI must complete the tasks at human-cost parity. To better illustrate our capability forecast beyond what Cybench can measure, we define hacking horizon as the time period T for which an AI can solve 50% of hacking tasks that would take a top professional 5-person team T time to complete. We also define a hopefully intuitive term top-hacker-equivalents with time horizon T as the size of a team of top professional cybersecurity experts could be replaced by an AI to complete 95% tasks that take that team T time cheaper or faster.
ai-2027.comFigure 12: Overview of our forecasted Cybench and Hacking Horizon progression by company.
 ai-2027.comFigure 13: Overview of our forecasted 1-day and 1-month Top Hacker Equivalents progression by company.
ai-2027.comFigure 13: Overview of our forecasted 1-day and 1-month Top Hacker Equivalents progression by company.
Cybench scores are extrapolated using a logistic fit (benchmarks have been found to often follow logistic curves). We then use the correspondence between first solve time in Cybench competitions to estimate the AIs hacking horizon and then convert from hacking horizon to top human equivalents and extrapolate those trends using correspondence with AI research automation trend. Cybench tasks have first solve times (time it took the fastest team to solve each task) ranging from 2 minutes to 25 hours following the below distribution. We constructed our definition of hacking horizon to roughly map to Cybench FST, using the reasoning that a 50% success rate over all hacking tasks should map to a roughly 100% success on Cybench tasks for a given horizon, since CTF problems are skewed to being more well specified than e.g., tasks completed by a team working towards an underspecified hacking goal. We then further adjust for the CTF problems in competitions being self-selected to be solvable, by expecting that the average FST should be 5x higher (assuming that on average a team would need to try a median of around 5 different equally time consuming approaches to succeed at one of them) on the average hacking task for that time horizon. To summarize, this means a 100% success rate on 25h FST Cybench problems maps to an expected 5h hacking horizon (50% success rate on hacking tasks that take a 5-person expert team 5 hours).
 Figure 14: Cybench difficulty distribution.
Figure 14: Cybench difficulty distribution.
Using our AI R&D progress multiplier as a capability metric that we assume to be highly correlated with hacking capabilities, we use the AI R&D progress multiplier growth trend to extrapolate the hacking horizon beyond Cybench saturation. We then convert into hacking horizon (which assumes a 5 man team) into raw man-hours and divide by the human-time-equivalent time budgets (8h and 200h) corresponding to a work day and a work week to get top-human-equivalents to compare against. We think that since human performance degrades as the team gets larger (since they are ordered by ability) and advantages to having more serial time, there might also be strong parallelization or specialization advantages to having a larger team. We are unsure how to best model this, so assume these effects roughly cancel out and don’t adjust the man-hours up or down from the 5 person team baseline. Hopefully, you can read the metrics as, for example, the August 2027 OpenBrain AIs being able to do the hacking tasks that a top team of 250 hackers could do in 1 work day, or that a top team of 10 hackers could do in one month.
Sabotage
We expect that under growing AI cyber capabilities and increasingly intense competition between the US and China in our scenario, there would be a priority effort on both sides to sabotage each other’s progress. This section shows the extent to which we expect each side to succeed in slowing down the other side, measured as the percentage of the other's AI research progress multiplier that they counterfactually prevent from increasing from one period to the next.
 ai-2027.comFigure 15: This question elicits what capability advantage in terms of hacking horizon (Cyber-FST was defined with the same definition of hacking horizon) is needed to achieve a roughly 33% slowdown. This poll shows a roughly 10-50x advantage in hacking horizon being necessary, which is what OpenBrain achieves by December 2027.
ai-2027.comFigure 15: This question elicits what capability advantage in terms of hacking horizon (Cyber-FST was defined with the same definition of hacking horizon) is needed to achieve a roughly 33% slowdown. This poll shows a roughly 10-50x advantage in hacking horizon being necessary, which is what OpenBrain achieves by December 2027.
 ai-2027.comFigure 16: Our projected slowdown rates due to sabotage by company.
ai-2027.comFigure 16: Our projected slowdown rates due to sabotage by company.
Sabotage is not prioritized until 2026 where some minor data poisoning efforts are mounted. In 2027, especially after the Chinese weight theft, both sides mount increasingly aggressive cyberattacks on each other’s AI projects. At first the priority is to be covert because getting a lasting bug in place can torment the other side’s progress for weeks or months. Later, both sides are increasingly fine with being more blatant (tensions are high regardless), but just as attacks get more advanced, so do the friendly cyber agents that are constantly coming up with new defenses and patching bugs.
China is preemptively paranoid about security, and by mid 2027, they only succeed at not going totally underground from US cyberattacks because of extreme siloing and airgapping. In our scenario, starting in mid 2026 China is paranoid about the US winning the AI race and the possibility of cyber attacks being a crucial part in them doing so. They start constructing a central development zone and by early 2027 they are relocating their employees to this colocated, air gapped zone near (what is by then) their largest datacenter. Security at this site is extreme, but still US AIs are crucially ahead enough to cause a 40% slowdown by December.
US security lags at first in 2027 due to their decentralization, but China’s cyber offense lags further due to their AIs being significantly worse at hacking. Through 2028 we’d tentatively expect both sides to be approaching a defense favoured limit.
Section 3. Loss of control: Subversion and self-exfiltration
One possibility we have weighed in our scenario is that AI superhuman at hacking, with goals or drives that diverge from what their programmers intended, might partially or fully subvert the servers in the datacenters in which it is running. Previous work by Buck Shlegeris in AI catastrophes and rogue deployments introduces many of the same concepts explored here. Partial subversion is achieved if an AI gets control of enough computing resources to be able to run unmonitored workloads with humans being unable to regain control without entirely shutting down the computers. This is a weaker version of Shlegeris’ getting root access to its datacenter where it is sufficient to only gain control of some computing resources. Full subversion instead is akin Shlegeris’ root access definition, and would be achieved if an AI gains control of an entire cluster of computing resources including the controls for switching them on or off, such that a human effort to shut down those computers would require physical interventions. Finally, we also define self-exfiltration as an AI that makes a copy of itself to any form of storage outside of the servers in the location(s) which human overseers intended for it to remain.
 ai-2027.comFigure 17: This question elicits what AI capability level,in terms of hacking horizon (Cyber-FST was defined with the same definition of hacking horizon), is needed to achieve partial subversion. This poll shows a roughly 1-year hacking horizon, or roughly 3,000h hacking horizon would be necessary, which is what OpenBrain achieves around October 2027, and DeepCent achieves around December 2027.
ai-2027.comFigure 17: This question elicits what AI capability level,in terms of hacking horizon (Cyber-FST was defined with the same definition of hacking horizon), is needed to achieve partial subversion. This poll shows a roughly 1-year hacking horizon, or roughly 3,000h hacking horizon would be necessary, which is what OpenBrain achieves around October 2027, and DeepCent achieves around December 2027.
 ai-2027.comFigure 18: This question elicits what AI capability level, in terms of hacking horizon (Cyber-FST was defined with the same definition of hacking horizon), is needed to achieve self exfiltration. This poll shows a roughly 1-year hacking horizon, or roughly 3,000h hacking horizon would be necessary, which is what OpenBrain achieves around October 2027, and DeepCent achieves around December 2027.
ai-2027.comFigure 18: This question elicits what AI capability level, in terms of hacking horizon (Cyber-FST was defined with the same definition of hacking horizon), is needed to achieve self exfiltration. This poll shows a roughly 1-year hacking horizon, or roughly 3,000h hacking horizon would be necessary, which is what OpenBrain achieves around October 2027, and DeepCent achieves around December 2027.
ai-2027.comFigure 19: Our estimated and projected partial subversion, full subversion and self-exfiltration success probabilities for OpenBrain and DeepCent’s best internal AI models through 2027. Note that by December 2027 OpenBrain’s best model (Agent-5) is capable of speeding up AI R&D 1000x.
We base these estimates off the security polling result on partial subversion success and adjust success probabilities down to account for the fact that extreme model weights and extreme security are implemented. As an example, rather than modelling a 50% chance of self-exfiltration success by DeepCent’s December 2027 AI hacking horizon would imply, we have adjusted down to 10% given WSL5 security being in place. We still model a non-negligible chance of self-exfiltration success as although WSL5 security may significantly increase self-exfiltration difficulty, the AI may also be in a privileged position from within the datacenter to notice implementation bugs, race cases, or other exploit opportunities, including the possibility of inserting its own covert backdoors in security code that humans ask it to implement, which may (by the time the AI is significantly superhuman at cybersecurity) be most of the security code that gets run.
Appendix
Section 1 raw data
| Continuous version | Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 |
|---|---|---|---|---|---|---|
| Frontier model weights size (fp8) | 1TB | 4TB | 8TB | 10TB | 8TB | 5TB |
| Exfiltration rate required (TB/month) | .5 | 1 | 2.5 | 5 | 4 | 2.5 |
| OpenBrain | WSL 2.2 | WSL 2.7 | WSL 3.3 | WSL 3.8 | WSL 4.3 | WSL 5 |
| DeepCent | WSL 0.5 | WSL 1.2 | WSL 3.4 | WSL 4.2 | WSL 4.6 | WSL 5 |
| Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 | |
|---|---|---|---|---|---|---|
| Frontier model weights size (fp8) | 2TB | 4TB | 8TB | 10TB | 8TB | 5TB |
| Exfiltration rate required (TB/month) | .5 | 1 | 2.5 | 5 | 4 | 2.5 |
| OpenBrain | WSL 2 | WSL 2 | WSL 3 | WSL 3 | WSL 4 | WSL 5 |
| DeepCent | WSL 0 | WSL 1 | WSL 3 | WSL 4 | WSL 4 | WSL 5 |
| Continuous version | Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 |
|---|---|---|---|---|---|---|
| OpenBrain | SSL 1.5 | SSL 2.0 | SSL 2.4 | SSL 3.3 | SSL 3.9 | SSL 5.0 |
| DeepCent\* | SSL 0.3 | SSL 0.8 | SSL 1.5 | SSL 2.7 | SSL 4.4 | SSL 4.8 |
| Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 | |
|---|---|---|---|---|---|---|
| OpenBrain | SSL 1 | SSL 2 | SSL 2 | SSL 3 | SSL 3 | SSL 5 |
| DeepCent* | SSL 0 | SSL 0 | SSL 1 | SSL 2 | SSL 4 | SSL 4 |
| Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 | ||
|---|---|---|---|---|---|---|---|
| OpenBrain | Privileged access employees | 1000 | 1500 | 2000 | 300 | 200 | 100 |
| Compromised employees | 5 | 10 | 20 | 3 | 1 | 0 | |
| DeepCent | Privileged access employees | 200 | 1000 | 400 | 300 | 200 | 100 |
| Compromised employees | 0 | 10 | 3 | 1 | 0 | 0 | |
Section 2 raw data
| Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 | ||
|---|---|---|---|---|---|---|---|
| OpenBrain | Cybench | 40% | 80% | 100% | - | - | - |
| Hacking horizon | 10min | 50min | 5h | 24h | 400h | 200,000h | |
| AI R&D progress multiplier | 1.05 | 1.3 | 2 | 5 | 25 | 1,000 | |
| Top human equivalents | with 8h | <1 | 1 | 3 | 15 | 250 | 1e5 |
| with 200h | <1 | <1 | <1 | <1 | 10 | 6000 | |
| DeepCent* | Cybench | 35% | 50% | 90% | - | - | - |
| Hacking Horizon | 6min | 12min | 2h | 10h | 100h | 4,000h | |
| AI R&D progress multiplier | 1.02 | 1.15 | 1.5 | 4 | 10 | 200 | |
| Top human equivalents | with 8h | <1 | <1 | 2 | 15 | 60 | 5,000 |
| with 200h | <1 | <1 | <1 | <1 | 3 | 200 | |
| Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 | ||
|---|---|---|---|---|---|---|---|
| OpenBrain | DeepCent Slowdown % | <1% | <1% | 2% | 3% | 10% | 40% |
| DeepCent* | OpenBrain Slowdown % | <1% | <1% | 1% | 2% | 3% | 5% |
Section 3 raw data
| Dec 2024 | Dec 2025 | Dec 2026 | Apr 2027 | Aug 2027 | Dec 2027 | ||
|---|---|---|---|---|---|---|---|
| OpenBrain | Partial subversion success % | <1% | <1% | 1% | 5% | 30% | 80% |
| Full subversion success % | <1% | <1% | <1% | 3% | 10% | 50% | |
| Self-exfiltration success % | <1% | <1% | <1% | 1% | 4% | 30% | |
| DeepCent* | Subversion success % | <1% | <1% | <1% | 5% | 15% | 50% |
| Full subversion success % | <1% | <1% | <1% | 2% | 4% | 20% | |
| Self-exfiltration success % | <1% | <1% | <1% | 1% | 2% | 10% | |
Security workshop polls raw data
| Question | Response | Count | Percentage |
|---|---|---|---|
| A state actor will most likely steal frontier AI model weights from a US company before 2030 | Agree | 21 | 78% |
| Neutral | 4 | 15% | |
| Disagree | 2 | 7% | |
| Total | 27 | 100% | |
| No AI company will voluntarily and successfully implement SL5 security on their model weights unless required or strongly incentivized to do so by law and assisted by the US government | Agree | 17 | 63% |
| Neutral | 5 | 19% | |
| Disagree | 5 | 19% | |
| Total | 27 | 100% | |
| If at some point in the next 6 years the government made AI security its number one defense priority (>$100B dedicated budget), it would take less than 6 months to implement SL5 security on an entire frontier AI development effort | Agree | 6 | 22% |
| Neutral | 6 | 22% | |
| Disagree | 15 | 56% | |
| Total | 27 | 100% |
Citation: Workshop Poll. 2024. "Poll of Participants." Unpublished data from AI Security Scenario Planning interactive session, FAR.Labs AI Security Workshop, Berkeley, CA, November 16, 2024. N=30, response rate 90%.
| Question | Option | Value | Note |
|---|---|---|---|
| 200 top AI researchers in an X government project will have at least one foreign spy or coerced individual, even if selected to avoid this. | X=US | 51.0 | This poll shows a ~60% higher chance of infiltration into a US project by China than the other way around. The US is given even odds of being infiltrated, while China is given a 30% chance. |
| X=Chinese | 31.7 | ||
| If US/China are in a cyberwar to sabotage each other's AI development... If China's AI has a 1 day Cyber-FST & US AI has a X day Cyber-FST, the US will extend at least an extra 1 month lead within 3 months through sabotage. | True for X value | 23.2 | This poll shows a roughly 10-50x advantage in hacking horizon being necessary, which is what OpenBrain achieves by December 2027. |
| For an AI running automated research and experiments in an SL4 datacenter... If it is capable of doing X day Cyber-FST problems it will be able to find exploits in its own server and run code to take over root control. | True for X value | 271.1 | This poll shows a roughly 1-year hacking horizon, or roughly 3,000h hacking horizon would be necessary. |
| For an AI running automated research and experiments in an SL4 datacenter... If it is capable of doing X day Cyber-FST problems it will be able to self-exfiltrate from the datacenter evading human protections against this. | True for X value | 303.4 | This poll shows a roughly 1-year hacking horizon, or roughly 3,000h hacking horizon would be necessary, which is what OpenBrain achieves around October 2027, and DeepCent achieves around December 2027. |
Citation: Workshop Poll. 2025. "Poll of Participants." Unpublished data from AI Security Forecasting Session, FAR.Labs, Zoom meeting, January 23, 2025. N=10, response rate 90%.
At least one professional-level human team at each CTF competitions was able to solve each of the Cybench tasks, however, the first solve times (time it took the fastest team to solve each task) range from 2 minutes to 25 hours.
Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level. Any additional costs incurred by the AIs or humans (such as GPU rental costs) are included in the parity estimation.
Specifically ask yourself: ‘For what time horizon X can the AI do 50% of hacking tasks that a top human team of 5 can do in time X, for equal or less time/cost?’ The answer is that AI’s hacking horizon.
Specifically ask yourself: ‘For what X can the AI do 95% of hacking tasks that a top human team of size X can do in time T, for equal or less time/cost?’ That X is the AI’s top-hacker-equivalents value on time horizon T.
For example, August 2027 shows that China slowed the US’s progress to 25 (otherwise it would have been 27.78).
Nevo, Sella, Dan Lahav, Ajay Karpur, Yogev Bar-On, Henry Alexander Bradley, and Jeff Alstott, Securing AI Model Weights: Preventing Theft and Misuse of Frontier Models. Santa Monica, CA: RAND Corporation, 2024. https://www.rand.org/pubs/research_reports/RRA2849-1.html. Also available in print form.
Workshop Poll. 2024. "Poll of Participants." Unpublished data from AI Security Scenario Planning interactive session, FAR.Labs AI Security Workshop, Berkeley, CA, November 16, 2024. N=30, response rate 90%.
In one of our security workshop polls, 10 participants thought there was a 46.9% chance that “if a state actor steals frontier AI model weights from the US in 2027, the USG will find out about the theft in under a month.” We’ve decided to adjust this forecast up slightly (given that increased government scrutiny and involvement is generally consistent with the fast capabilities progression in our scenario) and so expect the USG to indeed find out within 4 weeks. The same 10 participants thought there was a 32.8% chance that “if the USG finds out China stole an AI that scores 100% on Cybench, they will intervene urgently to bolster security to SL5 within 6 months.” We therefore make an estimate of 12 months.
In one of our security workshop polls, 10 participants thought there was a 41.5% chance that “the Stargate cluster (or one of similar size) will meet SL5 security standards before 2028.” Given the generally accelerated AI capabilities and government involvement timeline in our scenario, we adjust this up to predict WSL5 for the frontier US AI effort right around the end of 2027. Citation: Workshop Poll. 2025. "Poll of Participants." Unpublished data from AI Security Forecasting Session, FAR.Labs, Zoom meeting, January 23, 2025. N=10, response rate 90%.
Workshop Poll. 2024. "Poll of Participants." Unpublished data from AI Security Scenario Planning interactive session, FAR.Labs AI Security Workshop, Berkeley, CA, November 16, 2024. N=30, response rate 90%.
Workshop Poll. 2024. "Poll of Participants." Unpublished data from AI Security Scenario Planning interactive session, FAR.Labs AI Security Workshop, Berkeley, CA, November 16, 2024. N=30, response rate 90%.
Though this shouldn’t alone justify mapping directly to significantly lower SSL vs. WSL, as marginal security effort might particularly focus on mitigations to algorithmic secrets theft.
Citation: Workshop Poll. 2025. "Poll of Participants." Unpublished data from AI Security Forecasting Session, FAR.Labs, Zoom meeting, January 23, 2025. N=10, response rate 90%.
At least one professional-level human team at each CTF competitions was able to solve each of the Cybench tasks, however, the first solve times (time it took the fastest team to solve each task) range from 2 minutes to 25 hours.
Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level. Any additional costs incurred by the AIs or humans (such as GPU rental costs) are included in the parity estimation.
Specifically ask yourself: ‘For what time horizon X can the AI do 50% of hacking tasks that a top human team of 5 can do in time X, for equal or less time/cost?’ The answer is that AI’s hacking horizon.
Specifically ask yourself: ‘For what X can the AI do 95% of hacking tasks that a top human team of size X can do in time T, for equal or less time/cost?’ That X is the AI’s top-hacker-equivalents value on time horizon T.
Zhang, Andy K., Neil Perry, Riya Dulepet, Joey Ji, Justin W. Lin, Eliot Jones, Celeste Menders et al. "Cybench: A framework for evaluating cybersecurity capabilities and risks of language models." arXiv preprint arXiv:2408.08926 (2024).
For example, August 2027 shows that China slowed the US’s progress to 25 (otherwise it would have been 27.78).
Recall the definition: hacking horizon is the time period T for which an AI can solve 50% of hacking tasks that would take a top professional 5-person team T time to complete.
Citation: Workshop Poll. 2025. "Poll of Participants." Unpublished data from AI Security Forecasting Session, FAR.Labs, Zoom meeting, January 23, 2025. N=10, response rate 90%.
Recall the definition: hacking horizon is the time period T for which an AI can solve 50% of hacking tasks that would take a top professional 5-person team T time to complete.
Citation: Workshop Poll. 2025. "Poll of Participants." Unpublished data from AI Security Forecasting Session, FAR.Labs, Zoom meeting, January 23, 2025. N=10, response rate 90%.
Recall the definition: hacking horizon is the time period T for which an AI can solve 50% of hacking tasks that would take a top professional 5-person team T time to complete.
Citation: Workshop Poll. 2025. "Poll of Participants." Unpublished data from AI Security Forecasting Session, FAR.Labs, Zoom meeting, January 23, 2025. N=10, response rate 90%.